

Adapted from presentation at AG Open 2023.
If you are unfamiliar with HEMA, you may be unfamiliar with how different rule sets are from event to event. Because there is no unified governing body for HEMA, there is no universally-accepted rule set that events must use. There can be differences in all sorts of aspects of the events including, but not limited to:
- How many points an action scores
- The amount of time on a clock, if there is a clock at all
- The specifications and makers of swords that are allowed
- The criteria for a match win
- Which actions are legal in a match
- Algorithm for moving into eliminations
- The level of protective equipment necessary to participate

With all these differences, it becomes very important for a fighter to read the rules ahead of time in order to figure out what exactly they need to do to be able to fight and have success in a tournament. The question is, though, do fighters actually adapt their fighting style in order to take advantage of rule specifications? This article will look at one specific type of rule set gaming: scoring actions and their point values.
The Data
The data used for this analysis comes from two different events: Gesellen Fechten 2022 and SoCal Swordfight 2023 longsword tournaments. The reason for using these two events is that they have different point values for scoring targets, and both had a sizable amount of matches to gather data from– Gesellen Fechten with 172 matches in their first set of pools and SoCal Swordfight with 326 across four different skill tiers. SoCal Swordfight also used some of HEMA Scorecard’s best features, documenting exactly where and what type of attack was used (ex– cut to the head versus thrust to the torso). I was not so lucky with Gesellen Fechten, but did have access to over 7 hours of footage from a majority of the first set of pool matches where I was able to document attack type and target.

Targets and point values between Gesellen Fechten and SoCal Swordfight were different. For Gesellen Fechten, all hits were worth 1 point regardless of target or attack type. Socal Swordfight, on the other hand, can be used to make the case for rule set gaming as they have different point values for different types of targets and attacks:
- 3 Points: Cut or Thrust to the Head; Thrust to the Torso
- 1 Point: Cut to the Torso; Cut, Thrust, or Slice to the Limbs; Slice to the Head; Pommel to the Head
Only clean exchanges were used for this analysis. This means that strikes incurred on a double or afterblow situation are not included. For Gesellen Fechten, because data was from a video review, if the attack location was concealed or unclear, I did not record the exchange. This made for a total of 687 exchanges for Gesellen Fechten and 1538 exchanges for SoCal Swordfight used for this analysis. Based on what was scored, these are the 11 types of attacks noted:
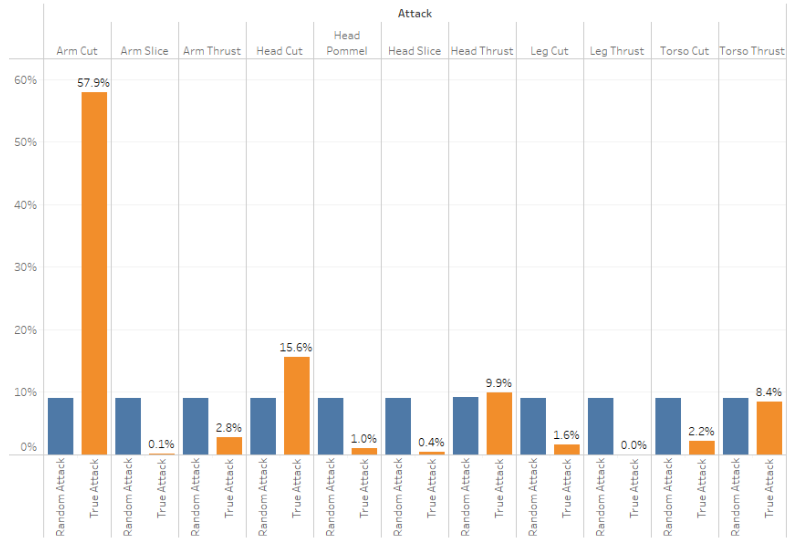
Gesellen Fechten
As mentioned previously, Gesellen Fechten’s rules for gaining points had every touch being one point. A thrust to the face counted for as much as a hit to the hands. The mentality behind this scoring system is that fighters should be practicing defense, and that each landed attack shows deficiencies in defense. With this sort of scoring system, we can assume that fighters will fence the way they are most comfortable fencing as they do not have to worry about which attacks will get them more points.
If a fighter threw an attack completely at random, there would be an even distribution of each of the combinations of attack type and target location. With 11 different options, this means each attack would occur about 9% of the time. Looking at the distribution of attacks from Gesellen Fechten, we can say with some certainty that fighters do have a preference for the type of attacks thrown and their targets:

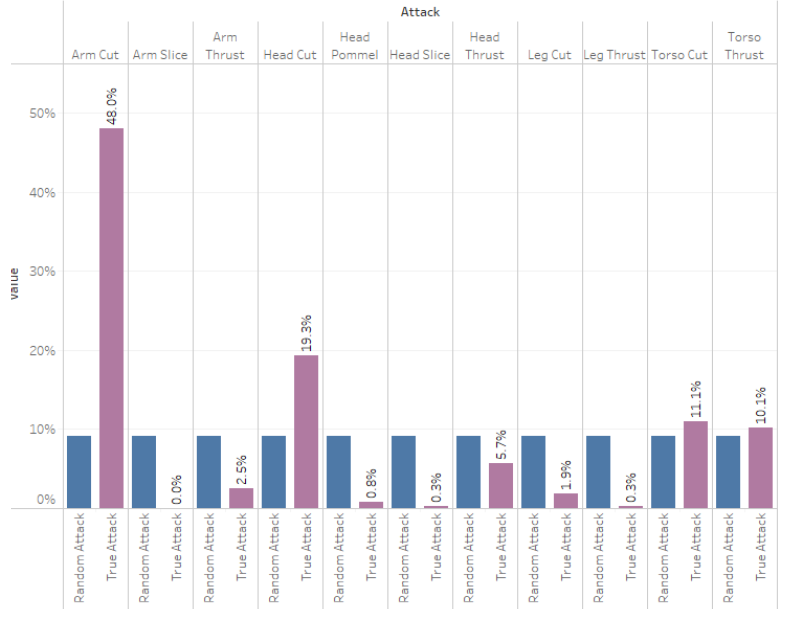
SoCal Swordfight
As mentioned earlier, SoCal Swordfight had different points for different targets. Head cuts and thrusts along with torso thrusts were worth 3 points whereas all other attacks were worth 1 point. The idea behind rewarding points this way is to influence competitors into performing attacks that are most supported by historical texts.
Looking at the data, we can see that, like Gesellen Fechten, there is not a true random distribution of attacks:
Comparing the Two Events
Let’s put the two events on the same graph to see if we can draw some conclusions about attack differences between the two events.
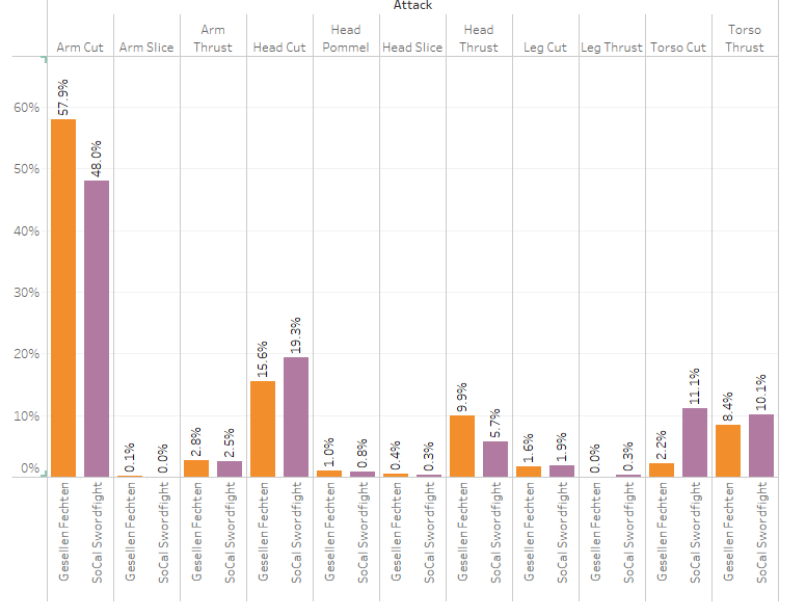
From this graph we notice that a couple of the categories have some pretty significant differences:
- Arm Cuts Decrease for SoCal (1 Point)
- Head Cuts Increase for SoCal (3 Points)
- Head Thrusts Decrease for SoCal (3 Points)
- Torso Cuts Increase for SoCal (1 Point)
- Torso Thrusts Increase for SoCal (3 Points)
From these observations, it isn’t actually clear whether or not fighters are gaming the rules. If we wanted to make a clear determination, all 1-point actions should decrease for SoCal while all 3-point actions should increase, but they show a mixed bag. It is easy enough, however, to convert this to a visual that provides a better comparison:
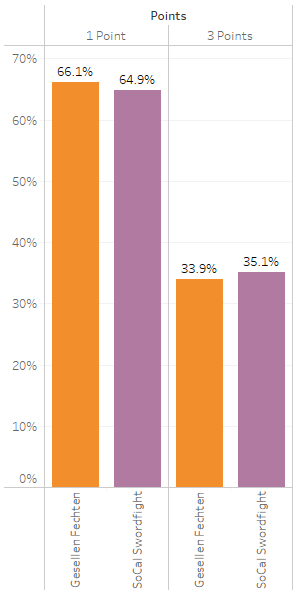
From this graph, we can see that SoCal Swordfight had a slight inclination for fighters performing 3-point attacks than fighters at Gesellen Fechten. However, is this slight difference just noise in the data, or is it enough to actually conclude that the fighters fought differently between events?

Statistical Significance Testing
Statistical significance testing is the proper way to say whether or not there is a difference between different values. The first step in doing significance testing is to set up your hypothesis. A hypothesis consists of the Null Hypothesis and the Alternative Hypothesis. The Null Hypothesis will assume that the two values we are looking at are statistically the same, meaning that any differences seen is due to noise. The Alternative Hypothesis will assume that the two values are different for reasons other than noise in the data. This is the formal notation for a hypothesis test:
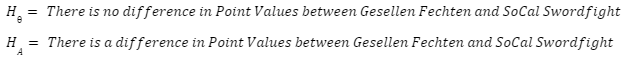
There are many different types of statistical significance tests that can be used, but they all depend on the underlying data. In this case, we are trying to do a test on data where both variables are categorical– in this case, the categories of event (Gesellen Fechten and SoCal Swordfight) and point value (1 Point and 3 Points). For this type of data, we will use a Chi-Square Test.
Statistical tests are evaluated with a p-value. “P” stands for “probability”, and the value is the probability that the differences between data points occurred by random chance. This means that lower p-values show that there is an actual difference rather than noise. In many statistical scenarios, we like our p-values to be below .05 to say that they are statistically significant.
After performing the chi-square test on the data, we find that there is a p-value of .58. In this case, because the p-value is so high, we fail to reject the null hypothesis and say that we do not have evidence to suggest that there is a difference in attacking high-value targets and low-value targets between these two events. In other words, there is a 58% likelihood that the differences seen between the two events are due to random chance.
Is There Anything Else?
Of course there’s something else that can be done! We can add more data to the mix to increase the sample size. If you’re wondering why this might matter, we can take a look at the below graphic:

Let’s think about this box as the students in a beginners’ HEMA class. The blue circles represent individuals interested in just longsword, while the gold star represents individuals interested in longsword and rapier. We know that the school also offers intermediate and advanced HEMA classes, and if we were to extrapolate weapon interest based on this information, we might think that the distribution looks like this:

However, in reality, we find that a lot of the time, as people grow more in HEMA, so do their interests in things other than longsword. So when polling more students that have more experience, we may find that the distribution of weapon interest looks more like this:

When we look at a higher percentage of the population, we can have higher certainty that the distribution we are seeing is the correct distribution.
(For more information on sample size, see Combat Con 2022: Why Sample Size Matters)
Now I’m going to include all historical SoCal Swordfight data where target and attack were recorded. This gives us a total of 3,053 exchanges that date back to 2018, and it shows us that there is a little bit more of a disposition to attacking high-value targets* at this event:
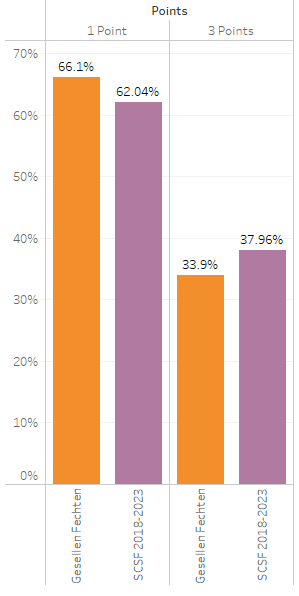
After running the chi square test for this data, it yields a p-value of .03. As mentioned in the prior section, we want our p-value to be less than .05 to consider the data significant. In this case, we now have statistical significance!
| *Note that for prior years of SoCal Swordfight, attacks did not necessarily follow a 1-point and 3-point distribution. Certain attacks were worth 4 points in prior years, though every attack that was high-value remained high-value (i.e., a 4-point target in past years was never subsequently worth 1 point). |
So What?
Though we have just proven that the targets attacked between Gesellen Fechten and SoCal Swordfight are statistically significant, there are some things to consider:
- Are the differences practically different? Even though there’s enough difference between 66% and 62% when taking into consideration their sample size to call them statistically different, is this a practical difference? That’s left up to interpretation.
- The differences seen might not be able to be attributed to rule set differences. One thing I’ve been told regularly is that fighters in different regions fight differently from each other. Even though there is some overlap between regions at these events, SoCal tends to draw mostly West Coast folk while Gesellen Fechten tends to draw mostly Midwest folk.
- Does the magnitude of point difference matter? Would we see more of a difference if the point values were 4 points for a head shot versus 3? Would we see less of a difference if it were 2 points? Unfortunately, I just don’t have enough data recorded in Scorecard to answer questions like this.
Regardless, what we can tentatively say is that the rule sets proposed by the event organizers are achieving their goal. SoCal Swordfight wants people to attack deep targets for fencing that emulates historical text better, and they are seeing more deep target attacks than at least Gesellen Fechten. Gesellen Fechten wants people to fight with a high degree of defense, and so they are punishing all targets equally– so even a hand sniper can win their fights.